

Tietokoneen muisti
Last modified: 2016-02-29 (Lisätty linkki stack/heap YouTube-videoon)
Nykyaikaisista tietokoneissa ja niiden käyttöjärjestelmissä on tyypillisesti käytössä virtuaalimuisti. Jokaiselle prosessille (eli karkeasti ottaen käyttäjän ajamalle ohjelmalle) on varattu oma muistiavaruutensa, jonka perusteella käyttöjärjestelmä ohjaa varsinaisen muistin käyttöä. Virtuaalimuisti suojaa ohjelman muistiavaruutta toisilta ohjelmilta, ja estää käyttäjän kirjoittaman ohjelman pääsyn toisten ohjelmien muistiavaruuteen. Normaalisti et voi siis kirjoittaa ohjelmaa, joka sotkisi toisten ohjelmien toimintaa. Oma ohjelma toki voi mennä sekaisin virheellisen muistinkäytön seurauksena.
Kukin ohjelma näkee siis oman 32- tai 64-bittisen muistiavaruutensa, josta tyypillisesti vain pieni osa on käytössä kerrallaan. Suurin osa muistipaikoista ei ole käytössä, ja viittaus tällaisiin osoitteisiin aiheuttaa "segmentation fault" signaalin käyttöjärjestelmältä. Muistiavaruus on jaettu erilaisiin lohkoihin sen perusteella, miten eri muistisegmenttejä on tarkoitus käyttää. Nämä lohkot on esitetty seuraavassa (yksinkertaistetussa) kuvassa:
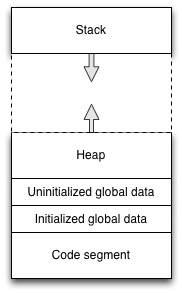
Ohjelman koodi ladataan kääntäjän tuottamasta ELF (Executable and Linking Format) - binääritiedostosta virtuaalimuistin kirjoitussuojattuun koodisegmenttiin. Täältä tietoa voidaan lukea, mutta muistialuetta ei voi muokata. Kun ohjelma käynnistyy, prosessori alkaa suorittaa ohjelmaa koodisegmentin alkupisteestä edeten ohjelmassa eteenpäin käskyjen määräämällä tavalla. Toisin kuin esimerkiksi Javan tai Pythonin tapauksessa, välissä ei ole tulkkiohjelmistoa, vaan tietokone suorittaa ohjelmaa suoraan ilman välikäsiä.
Myös vakiomuotoiset merkkijonot sijaitsevat virtuaalimuistin
kirjoitussuojatulla alueella, joka alustetaan ohjelmaa
ladattaessa. Esimerkiksi C-ohjelman rivi char *name = "Jaska";
aiheuttaa merkkijonon "Jaska" sijoittumisen tälle alueelle (muista
kuinka merkkijonoja määriteltiin). Näin ollen
name - osoittimen päässä olevaa merkkijonoa ei voi muuttaa. Jos näin
yritetään tehdä, käyttöjärjestelmä keskeyttää ohjelman segmentation
fault - signaaliin.
Koodisegmentin lisäksi, muistitilaa voidaan allokoida alustetulle globaalille datalle ("initialized global data") tai alustamattomalle globaalille datalle ("uninitialized global data"). Globaalisti määritellyt muuttujat (tai staattiset muuttujat) sijoittuvat tälle alueelle.
Keko ("heap") on dynaamisille muistinvarauksille käytettävää tilaa. Kun ohjelma varaa muistia malloc - funktiota käyttäen (nähdään pian), se sijoittuu virtuaalimuistin tälle alueelle. Dynaamisesti varattu muisti säilyy varattuna, kunnes se erikseen vapautetaan free - funktiokutsulla. Käyttöjärjestelmä säätelee keon kokoa dynaamisesti ohjelman tekemien muistivarausten perusteella.
Pino ("stack") on muistialue, jota tietokone varaa niinikään dynaamisesti, mutta ilman ohjelman suoraa ohjausta. Pinoon tallentuu muunmuassa lista funktioista, joiden kautta ollaan nykyiseen suorituskohtaan päädytty. Tietokoneen pitää muistaa nämä, jotta se osaa palata funktion loppuessa oikeaan kohtaan edellisessä funktiossa. Esimerkiksi debuggerin "call stack" tai "backtrace" - näkymä näyttää mitä funktioita pinossa tällä hetkellä on. Kunkin funktion argumenttien ja paikallisten muuttujien vaatima tila myöskin varataan pinosta. Kun funktiosta poistutaan, tämä tila vapautetaan saman tien. Sen takia virheellisiä osoittimia "vanhoihin" paikallisiin muuttujiin tulee välttää.
Toistaiseksi modulien 1 ja 2 esimerkeissa ja harjoitustehtävissä olemme käyttäneet pelkästään pinon kautta varattuja paikallisia muuttujia. Nyt alamme käyttämään kekoa ja siihen tarvittavia dynaamisia muistivarausmekanismeja.
YouTubesta löytyy havainnollinen video (n. 17 min) siitä kuinka pino ja keko toimivat C-ohjelman yhteydessä. Kannattaa siis jossain vaiheessa vilkaista sitäkin.
Dynaaminen muistihallinta
Muistin varaaminen ja vapauttaminen
Muistia varataan keosta malloc - funktiota käyttäen. malloc on
määritelty stdlib.h - otsakkeessa, eli kun haluat käyttää funktiota,
kyseinen otsake on sisällytettävä ohjelmaan #include <stdlib.h> -
komennolla. Myös muut tässä luvussa esitellyt muistinhallintafunktiot
on määritelty samassa otsakkeessa.
Ohjelmaa kirjoittaessa tulee vastaan useita tilanteita, jolloin muisti on varattava dynaamisesti, eikä paikallisia pinosta varattuja muuttujia voida käyttää:
-
Tarvittavan muistin määrä ei ole ohjelmointiaikana tiedossa, koska se esimerkiksi riippuu ohjelman muusta toiminnasta tai käyttäjän syötteistä.
-
Funktiota suorittaessa syntyy tilatietoa, jota on kuljetettava funktion ulkopuolelle muualle ohjelmaan. Funktion paikallisia muuttujia ei voi tällöin käyttää, koska ne tuhoutuvat funktiosta poistuttaessa.
-
Tiedetään että tarvittavan muistin määrä vaihtelee ohjelman suorituksen aikana, eikä haluta varata turhaan käyttämätöntä muistia.
malloc - funktion tarkka määritelmä on void *malloc(size_t
size). Funktio saa siis argumentikseen etumerkittömän kokonaisluvun
jota varten on määritelty uusi size_t - tyyppi. Tämä kertoo
varattavan muistin määrän tavuissa. Mikäli muistin varaus onnistuu,
funktio palauttaa osoittimen varatun muistialueen alkuun. Mikäli
varaus epäonnistuu, palautetaan vakio NULL, eli
"0-osoitin". Muistinvarauksen jälkeen onkin hyvä tarkastaa
paluuarvosta onnistuiko varaus, koska NULL-osoittimen käyttö johtaisi
muistivirheeseen ja ohjelman keskeytymiseen. Kuten tyypillisesti C:ssä,
varattu muisti on alustamatonta, eikä sen sisällöstä voi olettaa
mitään, ennenkuin ohjelma on kirjoittanut muistialueelle jotain.
void* - tietotyyppi viittaa geneeriseen osoittimeen, johon voi
tallettaa minkä tyyppistä tietoa tahansa. Tällainen osoitin voidaan
helposti sijoittaa minkä tahansa muun tyyppiseen osoittimeen, kuten
esimierkiksi int*, jonka jälkeen kääntäjä tietää, että kyseisen
muistialueen alkiot ovat int - tyyppisiä, ja osaa käsitellä
esimerkiksi osoitearitmetiikka oikein. void* - tyyppiseen
osoitteeseen osoitearitmetiikkaa ei voida soveltaa, eikä sitä yleensä
suoraan kannatakaan käyttää. On siis hyvä huomata, että malloc -
funktiolla on paluuarvo, joka on jokin osoitin.
Alla oleva esimerkki näyttää kuinka malloc - funktiota käytetään.
Kun muisti on onnistuneesti varattu rivillä 6, varatun muistialueen alkuosoite sijoitetaan table - muuttujaan. Tässä tapauksessa varataan tilaa 100:lle int - tyyppiselle arvolle, eli tehdään dynaamisesti varattu taulukko, jonka sisältö kirjoitetaan riviltä 11 alkavassa silmukassa.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | #include <stdlib.h> int main(void) { int *table; // uninitialized at this point table = malloc(100 * sizeof(int)); if (table == NULL) { return -1; // memory allocation failed } int i; for (i = 0; i < 100; i++) { table[i] = 100 - i; } free(table); } |
Kun taulukolle varataan muistia, on tärkeää ottaa huomioon taulukon alkion vaatima tila kun määritellään kuinka paljon muistia tarvitaan. malloc - argumentiksi annetaan aina tarvittava tila tavuissa, joten kun varaamme tilaa 100:lle int - tyyppiselle kokonaisluvulle, meidän on tiedettävä kuinka monta tavua yksi int - arvo tarvitsee muistista. Tämä tapahtuu sizeof - operaattorilla rivillä 6. malloc:lle siis kerrotaan, että tarvitsemme tilaa 100 kertaa yhden int:in tarvitseman koon. sizeof - operaattoria on käytännössä pakko käyttää vaikka luulisimme tietävämmekin, että int vie esimerkiksi neljä tavua, koska eri ympäristöissä int - tietotyypin koko voi vaihdella: sitä ei ole standardoitu.
Kun muisti on varattu, muistialuetta voi käyttää kuten mitä tahansa
taulukkoa, koska varattu muistiosoite on sijoitettu int * -
tyyppiseen muuttujaan. Kun taulukkoa nyt indeksoidaan (rivi 12),
kääntäjä osaa laskea mitä alkiota muistista käsitellään. Kuten
aiemminkin, kääntäjä ei osaa välttää tilannetta, jossa taulukkoa
indeksoidaan "yli" varatun alueen. Tällöin usein osutaan alueelle,
jota käyttöjärjestelmä ei ollut varannut ohjelman käyttöön, ja
aiheutetaan segmentation fault - signaali. Aina näin ei kuitenkaan
käy.
Kun muistia ei enää tarvita, se tulee vapauttaa free - funktiota käyttäen. free saa yhden parametrin, osoittimen aiemmin varatun muistialueen alkuun. Tämän osoittimen pitää olla sama, joka malloc - kutsusta on saatu. Osoitin johonkin varatun muistialueen keskelle aiheuttaa ajon aikaisen virheen. Varattua muistia ei voikaan vapauttaa "osittain", vaan vapautukset tapahtuvat samankokoisissa yksiköissä kuin varauksetkin on tehty.
Varatun muistilohkon voi vapauttaa vain kerran. Mikäli samaa muistialuetta yritetään vapauttaa toiseen kertaan, syntyy virhetilanne ja ohjelma keskeytyy.
Käyttämättömän muistin vapauttaminen on tärkeää, jotta järjestelmä saa muistin uuteen käyttöön. Ohjelman joka jättää vapauttamatta aiemmin varattua muistia sanotaan vuotavan muistia. Mikäli tällainen ohjelma pyörii järjestelmässä hieman pidemmän aikaa, se saattaa pikku hiljaa kuluttaa kaiken käytössä olevan muistin, mikä vaikuttaa muihin ohjelmiin, ja järjestelmän toimintaan kokonaisuudessaan, koska näiden muistin varaaminen vaikeutuu. Kun järjestelmän muisti on vähissä, sen toiminta tyypillisesti ensin hidastuu merkittävästi, ja tilanteen jatkuessa ohjelmia voidaan joutua keskeyttämään.
Aiemmin varatun muistialueen kokoa voidaan muuttaa realloc -
funktiolla. Funktion tarkka määrittely on void *realloc(void *ptr,
size_t size). Se saa parametrikseen osoittimen aiemmin varattuun
muistiin (ptr), sekä muistialueen uuden koon (size), joka voi olla
suurempi tai pienempi kuin muistialueen aiempi koko. Tämäkin funktio
palauttaa paluuarvonaan osoittimen säädetyn muistialueen alkuun.
realloc:in kanssa on hyvä huomioida, että muistialueen osoite saattaa muuttua kutsun seurauksena. Siksi paluuarvo kannattaa ottaa huolella käyttöön, eikä olettaa että muistialueen osoite olisi sama kuin ennenkin. Käytännössä voi ajatella että realloc koostuu loogisesti seuraavista operaatioista: 1) varataan uusi muistialue joka vastaa uutta kokoa; 2) Kopioidaan aiemman muistialueen sisältö (tai osa siitä, jos koko pienenee) uudelle muistialueelle; 3) vapautetaan vanha muistialue.
Alla oleva esimerkki näyttää kuinka realloc toimii:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | #include <stdlib.h> int main(void) { int *table; // uninitialized at this point table = malloc(100 * sizeof(int)); if (table == NULL) { return -1; // memory allocation failed } int i; for (i = 0; i < 100; i++) { table[i] = 100 - i; } int *newtable = realloc(table, 50 * sizeof(int)); if (!newtable) free(table); // realloc failed, old pointer still valid else free(newtable); // realloc succeeded, old pointer is released } |
Ohjelma alkaa kuten aiempi esimerkki, mutta rivillä 14 aiemmin varatun taulukon koko puolitetaan 50:n kokonaislukuun. realloc:in kanssa saa olla tarkkana mitä tapahtuu silloin kun muistialueen koon muuttaminen ei onnistukaan ja funktio palauttaa NULL. Tällöin aiempi muistialue säilyy edelleen varattuna. Tämän asia joudutaan ottamaan huomioon riveillä 15 ja 16, kun muistialuetta vapautetaan.
realloc:ia voi kutsua myös siten, että aiemman muistialueen osoitteeksi annetaan NULL. Tällöin toiminta vastaa malloc - funktion toimintaa.
Lisäksi muistin varausta varten on olemassa funktio calloc, joka
varaa N kappaletta tietyn kokoisia elementtejä ja lisäksi alustaa
muistin nollilla, muista muistinvarausfunktioista poiketen. Tarkka
muoto on void * calloc(size_t count, size_t size);. Voisi siis
esimerkiksi kutsua table = calloc(100, sizeof(int));.
Valgrindin käyttö
Valgrind on työkalu jolla voi analysoida ohjelman toimintaa eri tavoin, erityisesti liittyen sen muistinhallintaan. Valgrindin avulla voi jäljittää muistin käyttöön liittyviä virheitä, jotka muutoin saattaisivat olla vaikeita löytää, esimerkiksi kun virheellinen muistikäyttö aiheuttaa satunnaista väärää toimintaa. Valgrind löytää myös muistivuodot, sekä tapaukset joissa alustamatonta muistia käytetään osana ohjelmalogiikkaa.
Valgrindiä käytetään ohjelman ajon aikana. Ensin C-ohjelma käännetään
normaalisti suoritettavaksi tiedostoksi. Suoritettava tiedosti voidaan
ajaa valgrindin kanssa komennolla valgrind ohjelma, jossa ohjelma on
suoritettavan ohjelman nimi. Tällöin ohjelma toimii muuten
normaalisti, mutta valgrind analysoi sen toimintaa käsky
käskyltä. Sivuvaikutuksena tämä tyypillisesti hidastaa ohjelman
toimintaa merkittävästi.
Analysoitava ohjelma kannattaa kääntää -g kääntäjäoption kanssa,
jolloin suoritettavan ohjelman oheen tallentuvat viitteet
funktionimiin ja lähdekoodin rivinumeroihin, mikä helpottaa
valgrind-tulosteen lukemista merkittävästi. Kurssitehtävien mukana
tulevat Makefilet sisältävät tämän option aina.
Lisää tietoa Valgrindin toiminnasta ja käytöstä löytyy Valgrindin webbisivulta.
Valgrind on yleisesti saatavilla useimmissa Linux-jakelupaketeissa, mutta valitettavasti sen saatavuus Mac:llä ja Windowsilla on rajallinen. Mac:lle on olemassa versio Valgrindista, mutta ainakin allekirjoittaneella se toimii hyvin epävarmasti. Windowsille ei ole allekirjoittaneen tiedossa olevaa Valgrind-toteutusta. Kierrokselta 3 alkaen TMC-serveri ajaa aina Valgrindin tehtävien testaamisen yhteydessä, eikä päästä testejä läpi, mikäli Valgrind-virheitä esiintyy.
Seuraavassa esimerkkejä parista yksinkertaisesta Valgrind-virheestä. Oletetaan esimerkiksi seuraava (huonosti toteutettu) funktio, joka varaa muistia muistamatta koskaan vapauttaa sitä. Funktio pyrkii varamaan dynaamisesti muistia merkkijonolle (string), joka kopioidaan tähän muistialueelle (array). Muistialueen kuvitellaan sisältävän taulukon 80:n merkin mittaisia merkkijonoja.
1 2 3 4 5 6 7 8 9 10 11 12 | char *add_string(char *array, unsigned int *size, const char *string) { array = malloc(80 * (*size + 1)); if (array == NULL) { return NULL; } strncpy(&array[*size], string, 79); array[*size + 79] = 0; *size += 1; return array; } |
Kun ohjelma ajetaan Valgrindin kanssa, Valgrind tulostaa seuraavan ilmoituksen:
1 2 3 4 5 6 7 | ==358== 80 bytes in 1 blocks are definitely lost in loss record 29 of 34 ==358== at 0x4C244E8: malloc (vg_replace_malloc.c:236) ==358== by 0x401C50: add_string (source.c:3) ==358== by 0x4014E9: test_moduli3 (test_source.c:13) ==358== by 0x404B70: srunner_run_all (in /tmc/test/test) ==358== by 0x401894: tmc_run_tests (tmc-check.c:99) ==358== by 0x4015E8: main (test_source.c:38) |
Viesti kertoo muistivuodosta ("blocks are definitely lost"), eli muistia on varattua malloc:ia käyttäen rivillä 3., mutta sitä ei koskaan vapauteta. Valgrind ilmoitus viittaa funktioon add_string ja source.c - tiedoston riviin 3. Samassa ilmoituksessa näkyy myös kutsupino, eli ne funktiot joiden kautta ongelmalliseen funktioon on päädytty. Kaikissa listatuista funktioista ei siis ole virhettä. Virhettä kannattaa lähteä etsimään ensimmäisestä itse tekemästäsi funktiosta listasta, eli tässä tapauksessa add_string:stä. Tästä Valgrind-virheestä pääsee eroon, kun taulukolle varattu muisti vapautetaan jossain kohdassa ohjelmaa free - funktiolla.
Valgrind luokittelee muistivuotovirheet eri kategorioihin sen perusteella, ovatko varattujen muistialueiden osoitteet vielä tallessa. Joskus käy niin, että osoittimien ylläpito on toteutettu virheellisesti, esimerkiksi ohjelma kirjoittaa osoitinmuuttujan paikalle jotain muuta vapauttamatta ensin kyseistä muistialuetta. Tällöin muistia ei enää voi vapauttaa, vaikka ohjelmassa olisikin free - kutsu suunnilleen oikeassa paikassa.
Tässä hieman muokattu versio yllä olevasta ohjelmasta, joka aiheuttaa erilaisen Valgrind-virheen. Nyt ohjelma pyrkii kasvattamaan aiemmin varattua merkkijonotaulukkoa uudella parametrinaan saamallaan merkkijonolla (string). Kukin taulukon alkio sisältää siis tilaa 80:n merkin merkkijonolle.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | char *add_string(char *array, unsigned int *size, const char *string) { char *newarray = realloc(array, 80 * (*size)); if (newarray == NULL) { if (array) free(array); return NULL; } strncpy(&newarray[*size * 80], string, 79); newarray[(*size * 80) + 79] = 0; *size += 1; return newarray; } |
Nyt Valgrind tulostaa seuraavaa:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | ==358== Invalid write of size 1 ==358== at 0x4C25A4F: strncpy (mc_replace_strmem.c:339) ==358== by 0x401D33: add_string (source.c:10) ==358== by 0x401579: test_moduli3 (test_source.c:13) ==358== by 0x404C90: srunner_run_all (in /tmc/test/test) ==358== by 0x401924: tmc_run_tests (tmc-check.c:99) ==358== by 0x401678: main (test_source.c:38) ==358== Address 0x518c690 is 0 bytes after a block of size 0 alloc'd ==358== at 0x4C244E8: malloc (vg_replace_malloc.c:236) ==358== by 0x4C24562: realloc (vg_replace_malloc.c:525) ==358== by 0x401CE4: add_string (source.c:3) ==358== by 0x401579: test_moduli3 (test_source.c:13) ==358== by 0x404C90: srunner_run_all (in /tmc/test/test) ==358== by 0x401924: tmc_run_tests (tmc-check.c:99) ==358== by 0x401678: main (test_source.c:38) |
Virheilmoitus kertoo, että strncpy - funktio yrittää kirjoittaa virheelliseen muistipaikkaan, jota ei ole asianmukaisesti varattu ("invalid write of size 1"). Ilmoituksesta käy ilmi myös, että strncpy:ä kutsutaan add_string - funktion rivillä 10. Tämä on siis otollinen kohta aloittaa virheen etsintä.
size - muuttuja viittaa taulukon nykyisen kokoon (muistiviitteen
kautta). Jos esimerkiksi size on 1, taulukolle varataan tilaa 80
merkkiä rivillä 3. Rivillä 10 kuitenkin aletaan tällöin kopioida
merkkijonoa alkaen 80:stä merkistä, eli kopioitava merkkijono tulee
ylittämään varatun muistialueen koon, kun taas muistialueen alkua ei
käytetä hyväksi lainkaan. Kenties tarkoitus oli kopioida merkkijono
kohtaan &newarray[(*size - 1) * 80], jolloin muistialuetta ei
ylitettäisi.
Valgrind-ilmoituksessa viitataan myös realloc:iin rivillä 3. Tämä ei kuitenkaan tarkoita virhettä, vaan Valgrind kertoo vain, että strncpy:n ongelmallinen muistialue on varattu kyseisessä kohtaa ohjelmaa. Varsinainen ongelma on kuitenkin strncpy:n virheellinen käyttö.
Valgrindin kanssa on kohtuullisen tavallista, että yksi virhe ohjelmassa aiheuttaa ryöpyn virheitä, jotka palautuvat kyseiseen virheeseen. Siksi kannattaakin aloittaa Valgrind-ilmoitusten luku ensimmäisestä alkaen, ja keskittyä ensimmäisen virheen korjaamiseen. Samalla saattaa korjaantua moni muukin virhe.
Kertausta osoittimista
Edellisessä esimerkissä saattaa häiritä runsas osoitinviittausten käyttö. size - muuttuja ei olekaan pelkkä kokonaisluku, vaan viittaus kokonaislukuun jossain toisaalla ohjelmassa. Tämä johtuu siitä, että add_string - funktio kasvattaa kyseistä kokonaislukua yhdellä suorituksensa aikana. Muuttunut arvo halutaan pitää tallessa, joten varsinainen muuttuja säilytetään toisaalla ohjelmassa, ja funktion täytyy päivittää sitä osoittimen avulla. Muutokset paikallisessa muuttujassa häviäisivät heti kun funktiosta poistutaan.
&newarray[*size * 80] on myöskin osoitin. newarray[*size * 80]
tarkoittaa taulukon erästä alkiota, eli yhtä char - tyyppistä
arvoa. strncpy haluaa kuitenkin parametrikseen osoittimen, joten
& - operaattorilla haemme kyseisen alkion osoitteen. Tällöin
lausekkeen tietotyypiksi tulee char *. & - operaattori lisää
tietotyyppiin aina yhden "tähden".
Task 02_arrays_1: Dynaaminen taulukko (1 pts)
Tavoite: Tulet sinuiksi dynaamisen muistinvarauksen kanssa kokonaislukutaulukon yhteydessä.
Toteuta funktio dyn_reader joka varaa taulukon int - tyyppisille arvoille. Taulukossa tulee olla tilaa n:lle alkiolle. n annetaan funktiolle parametrina. Kun taulukko on varattu, sinun tulee lukea taulukon alkioille arvot käyttäjän syötteestä scanf - funktiota käyttäen. Kun vaadittu määrä kokonaislukuja on luettu, funktio palauttaa osoittimen dynaamisesti varattuun taulukkoon.
Task 02_arrays_2: Lisää taulukkoon (1 pts)
Tavoite: Harjoittele dynaamisesti varatun taulukon koon kasvattamista.
Toteuta funktio add_to_array joka lisää yhden kokonaisluvun aiemmin dynaamisesti varattuun taulukkoon (arr). Taulukon aiempi koko annetaan parametrissa num, ja uusi lisättävä kokonaisluku kerrotaan parametrissa newval. Varmista että taulukossa on riittävästi tilaa uuden kokonaisluvun lisäämiseksi, ja testaa että funktio toimii, kun sitä kutsutaan useita kertoja peräkkäin.
Funktioita muistin käsittelyyn
string.h - otsakkeessa määritellään funktioita muistin sisällön käsittelyyn, esimerkiksi kopiointiin ja tiedon siirtoon liittyen. Näistä saattaa olla joissain tilanteissa hyötyä. Funktiot ovat saman kaltaisia kuin modulissa 2 esitellyt merkkijonofunktiot, mutta erona on se, että seuraavassa olevat funktiot eivät käsittele 0-merkkiä mitenkään erityisellä tavalla. Toisin sanoen ne eivät oleta että käsiteltävät muistialueet sisältävät merkkijonoja.
-
memcpy kopioi osan muistista toiseen osoitteeseen. Funktion tarkka muoto on
void *memcpy(void *destination, const void *source, size_t n). source on osoitin muistialueeseen joka kopoidaan, ja destination kertoo mihin osoitteeseen kyseinen alue kopioidaan. n kertoo kuinka monta tavua kopioidaan. Funktio kopioi aina tämän määrän tavuja, riippumatta siitä kuinka monta nollamerkkiä tulee vastaan. Kannattaa huomioida että argumentit ovatvoid*- osoittimia, eli niiden paikalla voidaan käyttää mitä tahansa osoittimia. On myös hyvä huolehtia, että kohdeosoitteessa on varattuna riittävästi muistia, eli vähintäänkin n tavua. -
memmove on muuten samanlainen kuin memcpy, mutta se toimii myös silloin kun source ja destination ovat osittain päällekkäiset. memcpy (tai strcpy) eivät sitä salli. Funktion tarkka muoto on
void *memmove(void *destination, const void *source, size_t n). -
memcmp vertailee kahta muistilohkoa. Tarkka muoto on
int memcmp(const void *mem1, const void *mem2, size_t n). mem1 ja mem2 ovat kaksi vertailtavaa muistilohkoa, joista n tavua vertaillaan. Funktio palauttaa 0 jos muistilohkot ovat samat, tai erisuuri kuin 0, mikäli ne poikkeavat toisistaan. -
memset täyttää muistialueen sisällön annetulla arvolla. Tarkka muoto on
void *memset(void *mem, int c, size_t len). mem viittaa käsiteltävään muistialueeseen, c on 8-bittinen arvo, joka muistialueen jokaiseen tavuun kirjoitetaan, ja len kertoo kuinka monta tavua kirjoitetaan. Funktion tyypillinen käyttö on esimerkiksi annetun muistialueen täyttäminen 0:lla.
Alla esimerkki jossa näitä funktioita käytetään.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | #include <string.h> // memset, memcpy, memcmp, ... #include <stdlib.h> // malloc, free #include <stdio.h> // printf int main(void) { char *mem1, *mem2; mem1 = malloc(1000); if (!mem1) { printf("Memory allocation failed\n"); exit(-1); // no use continuing this program } mem2 = malloc(1000); if (!mem2) { printf("Memory allocation failed\n"); free(mem1); exit(-1); // terminating } memset(mem1, 1, 1000); memset(mem2, 0, 1000); if (memcmp(mem1, mem2, 1000) != 0) { printf("the memory blocks differ\n"); } memcpy(mem2, mem1, 1000); if (memcmp(mem1, mem2, 1000) == 0) { printf("the memory blocks are same\n"); } free(mem1); free(mem2); } |
Task 03_join: Liitä taulukot (1 pts)
Tavoite: Harjoittele muistinkäsittelyfunktioita. Lisäksi tällä kertaa teet oman lähdetiedostosi ja siihen liittyvät otsakemäärittelyt itse.
Toteuta funktio join_arrays joka saa parametrikseen kolme kokonaislukutaulukkoa, sekä kustakin taulukosta sen alkioiden lukumäärän. Kaikkiaan funktio saa siis kuusi parametria, jotka on esiteltävä tässä järjestyksessä:
- ensimmäisen taulukon alkioiden lukumäärä (unsigned integer)
- osoitin ensimmäiseen kokonaislukutaulukkoon (alkiot tyyppiä int)
- toisen taulukon alkioiden lukumäärä (unsigned integer)
- osoitin toiseen kokonaislukutaulukkoon (tyyppiä int)
- kolmannen taulukon alkioiden lukumäärä (unsigned integer)
- osoitin kolmanteen kokonaislukutaulukkoon (tyyppiä int)
Funktion tulee liittää nämä kolme taulukkoa yhdeksi taulukoksi, joka sisältää kaikki kolmessa taulukossa listatut kokonaisluvut yllä mainitussa järjestyksessä. Uusi yhdistetty taulukko tulee varata dynaamisesti ja funktion tulee palauttaa osoitin tähän uuteen taulukkoon. Et saa muuttaa alkuperäisiä taulukoita mitenkään.
main.c - tiedoston main-funktiosta näet esimerkin kuinka yllä kuvattua funktiota kutsutaan. source.c:n lisäksi sinun pitää muokata source.h - tiedostoa, jotta main - funktio ja tehtävän testit näkevät toteuttamasi funktion. Muista myös sisällyttää tarvitsemasi C-kirjaston otsakkeet. Huomaa että alkutilassa ohjelma ei edes käänny, ennenkuin olet toteuttanut vähintäänkin jonkinlaisen rungon join_arrays - funktiosta, joka vastaa main.c:n olettamaa funktiorajapintaa.
Rakenteiset tietotyypit
Tosiinsa liittyviä muuttujia voi koota yhteen omaksi koostetuksi tietotyypikseen rakenteisten tietotyyppien (struct) avulla. Rakenteisella tietotyypillä on nimi, jonka avulla sitä voidaan käyttää muuttujissa, sekä funktioiden parametreinä ja paluuarvona, tai ylipäätään missä tietotyyppejä normaalistikin käytetään. Rakenteista tietotyyppiä voi käyttää osoittimien kanssa kyten muitakin tietotyyppejä, ja voipa rakenteinen tietotyyppi olla osa jonkin toisen rakenteisen tietotyypin määrittelyä.
Rakenteisen tietotyypin määrittely
Rakenteinen tietotyyppi määritellään struct määreen avulla. Rakenteinen tietotyyppi koostuu kentistä, joilla kullakin on nimi sekä tietotyyppi, joka on joku C:n perustietotyypeistä, tai jokin muu, aiemmin määritelty tietotyyppi. Kentän tietotyyppi voi myös olla taulukko tai osoitin.
Alla on esimerkki rakenteisen tietotyypin "person" määrittelystä. Tietotyypin kentät määritellään omassa lohkossaan aaltosulkeiden sisällä, ja kunkin kentän määrittely loppuu puolipisteeseen. Tietotyypissä person on kaksi kenttää: 'name' - kenttä on ilmeisestikin merkkijono, eli osoitin char - taulukon alkuun. Lisäksi const-määrittely kertoo, että nimi-merkkijonoa ei voi muokata sen jälkeen kun se on sijoitettu rakenteiseen tietotyyppiin. Tämän lisäksi person - rakenteessa on kenttä 'age', joka on kokonaisluku. Myös rakenteen määrittelyn lopussa, aaltosulun perässä, käytetään puolipistettä.
1 2 3 4 | struct person { const char *name; int age; }; |
Yllä oleva ohjelmanpätkä ei tee muuta kuin määrittelee uuden tietotyypin. Yhtään kyseistä rakennetta käyttävää muuttujaa ei ole vielä määritelty. Muuttujia voi määritellä tietotyypin määrittelyn yhteydessä lisäämällä niitä tietotyyppimäärittelyn perään seuraavasti:
1 2 3 4 | struct person { const char *name; int age; } guyA, guyB; |
Nyt meillä on kaksi muuttujaa, guyA ja guyB, jotka molemmat tallentavat rakenteista tietotyyppiä vastaavan tietojoukon, eli nimen ja iän.
On myös mahdollista määritellä muuttujat, mutta jättää rakenteinen tietotyyppi nimeämättä:
1 2 3 4 | struct { const char *name; int age; } guyA, guyB; |
Tämä on harvinaisempaa, koska useimmiten tietotyypin nimeämisestä on
hyötyä. Tietotyypin nimen avulla rakenteiseen tietotyyppiin voidaan
viitata toisaalla ohjelmassa ilman että sen kenttiä tarvitsee jälleen
uudelleen määritellä. Esimerkiksi struct person jussi; määrittelee
uuden muuttujan nimeltään jussi, joka noudattaa aiemmin määriteltyä
rakenteista tietotyyppiä.
Koska suuret ohjelmistot on usein jaettu useisiin ohjelmamoduleihin (eli .c - tyyppisiin lähdetiedostoihin), joissa saattaa olla tarvetta käyttää samoja rakenteisia tietotyyppejä, tapana on esitellä rakenteiset tietotyypit .h - päätteisissä otsaketiedostoissa, jolloin kyseinen tietotyyppi saadaan käyttöön useaan ohjelmamoduliin sisällyttämällä otsake ohjelmaan #include - direktiiviä käyttäen.
Rakenteisen tietotyypin käyttäminen
Kun rakenteinen tietotyyppi on määritelty, sitä voidaan käyttää uusien muuttujien esittelyyn tai funktioiden parametreina, paljolti kuten C:n perustietotyyppejäkin. Kun rakenteista tietotyyppiä käyttävää muuttujaa käsitellään, joudutaan usein käsittelemään suoraan tietotyypin yksittäisiä kenttiä. Tämä onnistuu piste-notaatiolla: muuttujan nimen ja käsiteltävän kentän nimi erotetaan pisteellä. Seuraava esimerkki valaisee miten tämä toimii.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | #include <stdio.h> struct person { const char *name; int age; }; int main(void) { struct person lady = { "Kirsi", 22 }; struct person dude; dude.name = "Pertti"; // note "const char*" in the name field dude.age = 40; printf("name of lady: %s\n", lady.name); } |
Esimerkin tapauksessa person - tietotyyppiä ei ole määritelty otsakkeessa, vaan C-lähdetiedostossa, mikä on teknisesti ottaen mahdollista. Sen jälkeen main - funktiossa esitellään muuttuja lady, joka alustetaan muuttujan esittelyn yhteydessä. Tässä kannattaa huomioida alustuksessa käytetty notaatio: Rakenteisen tietotyypin kenttiin sijoitettavat arvot listataan aaltosulkeiden sisällä pilkulla erotettuna. Parametrien tyyppien tulee vastata rakenteen määrittelyä, eli tässä tapauksessa ensin annetaan merkkijono, ja toiseksi kokonaisluku.
On myös mahdollista jättää muuttuja alustamatta, kuten tehdään muuttujan dude tapauksessa. Tällöin C:lle tyypillisesti tietotyypin kenttien sisältö saattaa olla mitä tahansa, kunnes niille on asetettu jokin arvo. Riveillä 12 ja 13 nähdään kuinka rakenteisen tietotyypin kenttiin sijoitetaan arvot. Ensin kerrotaan mitä muuttujaa käsitellään, ja pisteellä erotettuna mitä kenttää käsitellään. Rakenteisen tietotyypin kenttiä voi käyttää lausekkeessa kuten muitakin muuttujia, kuten nähdään printf:n yhteydessä rivillä 14.
Taulukoista poiketen rakenteista tietotyyppiä käyttävä muuttuja voidaan sijoittaa suoraan toiseen muuttujaan yksinkertaisella sijoituslausekkeella, kuten alla olevassa esimerkissä tehdään. Tällöin kaikki kentät kopioituvat muuttujasta toiseen. Kuten muistetaan, kokonaisia taulukoita ei samalla tavalla voi kopioida, elleivät ne sisälly rakenteiseen tietotyyppiin.
1 2 3 | struct person lady = { "Kirsi", 22 }; struct person dude; dude = lady; // what?? |
Yllä olevan sijoituksen voisi tehdä myös memcpy:ä käyttäen:
memcpy(&dude, &lady, sizeof(struct person));, mutta
sijoitusoperaattorin käyttö on toki useimmiten helpompaa. person -
rakenteen tapauksessa on hyvä huomioida, että itse merkkijonoa ei
kopioida, koska rakenteessa tallennetaan vain osoitin
merkkijonoon. Sijoituksen jälkeen dude ja lady viittaavaat samaan
muistiosoitteeseen ja samaan merkkijonoon. Koska tietotyyppi oli
määritelty muuttumattomaksi const - määreellä, tämä ei
todennäköisesti haittaa ohjelman toimintaa.
Rakenteista tietotyyppiä voi käyttää funktion parametrina esimerkiksi seuraavaan tyyliin:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | #include <stdio.h> struct person { const char *name; int age; }; int has_enough_age(struct person p) { if (p.age >= 18) return 1; else return 0; } int main(void) { struct person guy = { "Kalle", 22 }; if (has_enough_age(guy)) { printf("You may enter!\n"); } } |
Koska C:ssä funktioparametrien arvot kopioidaan funktion käyttöön, tietorakenteesta tehdään erillinen kopio has_enough_age - funktion pinokehykseen. Mikäli p - muuttujaa muutetaan, muutokset eivät näy main - funktiossa. Jos haluttaisiin muutosten heijastuvan myös kutsuvalle funktiolle, olisi parempi käyttää osoitinta alkuperäiseen guy - muuttujaan.
Rakenteista tietotyyppiä voidaan käyttää myös funktion paluuarvona, jolloin return - lauseessa annettu muuttuja ja sen kaikki kentät kopioituvat takaisin kutsujalle.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | int has_enough_age(struct person p) { if (p.age >= 18) return 1; else return 0; } struct person make_older(struct person p) { p.age++; return p; } int main(void) { struct person guy = { "Kalle", 15 }; while (!has_enough_age(guy)) { printf("waiting one year...\n"); guy = make_older(guy); } printf("age is now: %d\n", guy.age); } |
Yllä oleva ohjelma tulostaa seuraavaa:
1 2 3 4 | waiting one year... waiting one year... waiting one year... age is now: 18 |
Rakenteinen tietotyyppi ja osoittimet
Kuten muitakin tyyppejä, myös rakenteiseen tietotyyppiin voidaan
viitata osoittimella. Tällöin normaaliin tapaan tietotyypin nimen
perään annetaan tähtimerkki (*), merkkaamaan että kyseinen
tietotyyppi sisältää muistiosoitteen.
Koska rakenteisten tietotyyppien käyttö osoittimien kautta on melko
yleistä C:ssä, kieli määrittelee "nuolioperaattorin" (->), jolla viitataan
tietorakenteen kenttiin silloin kun käytössä on osoitin. Alla oleva
esimerkki näyttää miten tämä toimii:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | #include <stdlib.h> int main(void) { struct person lady = { "Kirsi", 15 }; struct person *kirsi = &lady; kirsi->age = 18; printf("age: %d\n", lady.age); struct person *guy; guy = malloc(sizeof(struct person)); guy->name = "Pertti"; guy->age = 40; free(guy); } |
Nuolioperaattori on periaatteessa optionaalinen: vastaavan C-kielisen
ohjelman voisi kirjoittaa myös ilman tätä operaattoria. Ylläolevan
ohjelman rivi 7 voitaisiin esittää myös näin: (*kirsi).age =
18;. Sulut ovat tässä tapauksessa pakollisia, koska pistenotaatio on
laskujärjestyksessä ennen viittausoperaattoria. Varsinkin
monimutkaisten tietorakenteiden kanssa tämä notaatio käy hankalaksi,
joten siksi nuolioperaattoria käytetään selkeyttämään ohjelmaa.
Ylläolevassa ohjelmassa kirsi on viittaus muuttujaan lady, ja kun ensimmäiseen kohdistetaan sijoitusoperaatio, käytännössä muutetaan rakenteisen muuttujan lady sisältöä.
Jälkimmäisessä osassa funktiota muodostamme uuden muuttujan guy, jolle varataan muisti dynaamisesti keosta käyttäen malloc - funktiota (rivi 11). Tällöin tietoa on pakko käsitellä osoittimen kautta, kuten tässä tehdään. Kun rakenteiselle tietotyypille varataan tilaa, sizeof - operaattori on käytännössä välttämätön: se kertoo kuinka paljon tilaa rakenne kokonaisuudessaan vie. Tätä ei kannata yrittää laskea itse, koska kääntäjä saataa lisätä tyhjiä välejä kenttien väliin tehostaakseen kenttien käsittelyä. Tietotyypin vaatima tila kokonaisuudessaan saattaa siis olla enemmän kuin kenttien kokojen yhteenlaskettu summa.
Osoitearitmetiikka toimii myös rakenteisten tietotyyppien kanssa, mikä mahdollistaa taulukoiden muodostamisen rakenteisista tietotyypeistä. Kun tällaista osoitinta "lisätään yhdellä", osoitin siirtyy eteenpäin suoraan rakenteisen tietotyypin vaatiman tilan verran, seuraavaan alkioon oletetussa taulukossa.
Seuraavassa hieman monimutkaisempi esimerkki, jossa käsitellään person - tietotyypistä koostettua taulukkoa. Olemme nyt muuttaneet myös hieman rakenteen määritelmää siten, että name - kenttä onkin nyt muutettavissa oleva merkkijono, eli const - määre on tiputettu pois.
Funktio määrittelee 10 alkion members taulukon, jossa kukin alkio on yksi person - rakenne. Kymmenen alkiota käydään läpi, ja kussakin tapauksessa nimelle varataan malloc:ia käyttäen riittävästi tilaa, ja sitten generoidaan kullekin henkilölle yksillöllinen (mutta mielikuvitukseton) nimi: "guy-A", "guy-B", jne... Kannattaa kiinnittää huomiota missä järjestyksessä taulukon indeksointi tapahtuu, ennen kuin tietorakenteen kenttiin viitataan. Toisaalta name - kenttä on myös itsessään merkkijonotaulukko, eli sitäkin voi indeksoida, kuten tässä nimeä generoidessa tehdäänkin.
Kannattaa myös huomioida varatun muistin vapautus lopussa: se pitää tehdä erikseen kullekin taulukon nimelle, koska malloc kutsuttiin erikseen jokaiselle nimelle. free - kutsujen määrän pitää vastata malloc - kutsujen määrää.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | #include <stdio.h> #include <stdlib.h> #include <string.h> struct person { char *name; int age; }; int main(void) { struct person members[10]; struct person *current = &members[0]; int count = 0; char *nameprefix = "guy-"; const int NameLen = 5; /* Need to allocate name separately, because structure does not reserve space for it */ for (int i = 0; i < 10; i++) { members[i].name = malloc(NameLen + 1); // if malloc does not succeed, name remains unspecified if (members[i].name) { /* Dynamically build unique name for each member: "guy-A", "guy-B", "guy-C", .... */ strcpy(members[i].name, nameprefix); members[i].name[4] = 'A' + i; members[i].name[NameLen] = '\0'; } members[i].age = i + 60; } // find first person who is at least 65 years old /* could also use: members[count].age */ while (count < 10 && current->age < 65) { current++; // move to next element in array count++; } // in principle we might have not succeeded allocating all names // therefore current->name could be NULL if (count < 10 && current->name) { printf("found: %s, age: %d\n", current->name, current->age); // or: printf("found: %s", members[count].name); } // remember to release allocated memory for (int i = 0; i < 10; i++) { if (members[i].name) free(members[i].name); } } |
Yksi vaihtoehto olisi ollut määritellä tietorakenne person seuraavasti:
1 2 3 4 | struct person { char name[20]; int age; }; |
Tällöin erillistä malloc - varausta ei tarvittaisi, koska kullekin nimelle varataan 20 merkin verran tilaa osana person - tietorakennetta, ja kääntäjä varaa tämän tilan automaattisesti (pinosta) samalla kun muuttujaa tai taulukkoa esitellään.
Dynaamisesti varattu taulukko
Joskus tarvitsemme vaihtelevan määrän tietoalkioita, jotka kaikki noudattavat samaa rakenteista tietotyyppiä. Tällöin rakenteet voidaan tallentaa taulukkoon, kuten edellä nähtiin, mutta mikäli emme ohjelmointivaiheessa tiedä kuinka monta tietoalkiota ohjelma tulee tarvitsemaan, tarvittava tila täytyy varata dynaamisesti, ja tilaa tulee tarvittaessa kasvattaa kun uusia tietoalkioita tulee saataville.
Muisti varataan tietysti malloc - kutsulla, mutta pitää olla tarkkana sen suhteen kuinka paljon muistia tarvitsemme. Alla oleva ohjelma varaa dynaamisesti taulukon tutuksi tulleelle person - rakenteelle.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | #include <string.h> #include <stdlib.h> struct person { char *name; int age; }; int main(void) { struct person *people; int num_people = 10; const char *defaultname = "John Doe"; people = malloc(sizeof(struct person) * num_people); for (int i = 0; i < num_people; i++) { people[i].name = malloc(strlen(defaultname) + 1); strcpy(people[i].name, defaultname); people[i].age = i + 30; } // do something else for (int i = 0; i < num_people; i++) { free(people[i].name); } free(people); } |
Rivillä 15 varataan malloc:ia käyttäen riittävästi tilaa 10 henkilölle. Kukin henkilö vie sizeof(struct person) tavua tilaa. Tässä tapauksessa olemme luottavaisa, emmekä testaa onnistuiko muistin varaus. Mikäli se ei onnistu, malloc palauttaa NULL-osoittimen ja ohjelma kaatuu segmentation fault - virheeseen kun yrittämme käyttää people - taulukkoa.
Muistin varaamisen jälkeen people - muuttujaa voidaan käyttää kuten mitä tahansa taulukkoa: sitä voidaan indeksoida normaalisti, ja yksittäisiin kenttiin viitataan kuten ennenkin.
Taulukon varaamisen lisäksi kullekin tietoalkiolle pitää erikseen varata tila name - merkkijonolle, koska tietorakenteen määrittely sisälsi pelkän osoittimen. Tätä varten kutsumme malloc:ia uudestaan jokaisen alkion kohdalla, ja varaamme tilaa riittävästi jotta defaultname saadaan kopioitua varattuun paikkaan. Merkkijono pitää siis kopioida strcpy - funktiota käyttäen. Suora sijoitus aiheuttaisi väärän lopputuloksen.
Kun taulukkoa ei enää tarvita, sen vaatima tila vapautetaan free - funktiota käyttäen. Koska kussakin alkiossa oli dynaamisesti varattu merkkijono, myös ne pitää vapauttaa erikseen kustakin alkiosta. Lopuksi koko taulukko voidaan vapauttaa yhdellä free - kutsulla, koska taulukon varaaminenkin tapahtui yhdellä malloc - kutsulla.
Mikäli taulukkoon tarvitsee myöhemmin lisätä alkiota, sen kokoa täytyy kasvattaa realloc - funktiota käyttäen.
Etukäteismäärittely
On kohtuullisen tavallista, että rakenteisen tietotyypin määrittelyssä viitataan toisiin rakenteisiin tietotyyppeihin. Jotta johonkin tietotyyppiin voitaisiin viitata, kyseinen tietotyyppi tulee määritellä ensiksi. Joskus tulee vastaan kehämäisiä tilanteita, joissa tietotyyppien väliset viittaukset menevät ristiin, eikä ole mahdollista rakentaa ohjelmaa siten, ettei tarvittaisi viittausta tyyppiin jota ei ole vielä esitelty. Tällöin kääntäjälle täytyy kertoa, että "tämän nimisen tietotyypin määrittely seuraa hetken perästä, mutta tässä vaiheessa riittää tietää, että tämänniminen tyyppi on olemassa". Tällaista kutsutaan etukäteismäärittelyksi (forward declaration), ja se tehdään alla olevan ohjelman rivillä 3. Rakenteiden person ja pet keskinäisen järjestyksen vaihtaminen ei ratkaise ongelmaa, että tietorakenteen sisällä on viittaus aiemmin määrittelemättömään tietotyyppiin.
Etukäteismäärittely toimii vain osoittimien yhteydessä: kääntäjä tietää, että osoitin vie aina muistiosoitteen verran tilaa, mutta se ei pysty varaamaan tilaa varsinaiselle rakenteelle ennenkuin se on määritelty.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | #include <stdio.h> struct pet; struct person { const char *name; int age; struct person *marriedTo; struct pet *myPet; }; struct pet { struct person *owner; const char *name; }; int main(void) { struct person man = { "Jorma", 50, NULL, NULL }; struct person lady = { "Kirsi", 15, &man, NULL }; struct pet cat = { &lady, "Kisu" }; man.marriedTo = &lady; lady.myPet = &cat; printf("Name of the cat: %s\n", man.marriedTo->myPet->name); } |
Ylläolevassa ohjelmassa person - rakenteeseen on siis lisätty kaksi uutta kenttää: osoitin toiseen henkilöön (marriedTo) ja osoitin pet - tyyppiseen rakenteeseen. Molemmissa on pakko käyttää osoitinta, koska kyseisessä kohdassa kääntäjä ei vielä tiedä paljonko tietorakenteet vaativat tilaa.
Ohjelman lopussa on main - funktio, joka esittelee pari henkilöä, sekä lemmikin, sekä asettaa niiden väliset viitteet. Sisäkkäisten tietorakenteiden kenttien välillä voidaan ketjuttaa viittauksia jotta päästään käsiksi haluttuun kenttään, kuten ohjelman lopussa olevassa printf - lauseessa tehdään. Pystytkö seuraamaan mitä ohjelma tulostaa? (sen voi aina kopioida omaan editoriin ja kääntää itse)
Task 04_vessel: Laiva (1 pts)
Last modified: 2016-03-11 (Lisätty pari sanaa osoittimista ja mallocista)
Tavoite: Harjoitellaan rakenteisten tietotyyppien määrittelyä ja peruskäyttöä.
Tässä harjoituksessa sinun tulee toteuttaa kolme asiaa: 1) määrittele rakenteinen tietotyyppi vessel, joka kuvaa kuvitteellista valtamerialusta; 2) toteuta funktio create_vessel joka luo uuden instanssin määrittelemästäsi vessel - tietotyypistä; 3) toteuta funktio print_vessel joka tulostaa vessel - rakenteen sisällön.
vessel - tietorakenteessa tulee olla seuraavat kentät. On tärkeää että kenttien nimet ovat kuten alla annettu, koska muuten src/main.c tai tehtävän testikoodit eivät käänny.
-
name: laivan nimi merkkijonona. Merkkijono tulee kopioida create_vessel - funktion parametrista p_name. Et voi sijoittaa sitä suoralla sijoitusoperaattorilla. Nimeä tulee voida muokata jälkeenpäin, ja siinä on oltava tilaa 30 merkille (plus lopetusmerkki). Tila on varattava pinosta (stack) eikä keosta (heap), eli älä käytä dynaamista muistia tähän. Jos funktion parametrina annettu nimi on pidempi kuin 30 merkkiä, se tulee katkaista 30 merkkiin.
-
length: laivan pituus double-tyyppisenä liukulukuna. Voit olettaa että pituus ilmaistaan metreinä (tosin asialla ei suurta käytännön merkitystä tässä tehtävässä).
-
depth: laivan syväys double-tyyppisenä liukulukuna. Tämänkin osalta voi olettaa että syväys ilmaistaan metreinä.
-
crg: laivan lasti. Tämän tulisi vastata yhtä cargo - tietorakennetta, joka on annettu source.h - otsakkeessa.
Sinun tulee määritellä vessel - rakenne source.h - otsaketiedostossa, jotta muut lähdetiedostot näkevät sen.
create_vessel saa vastaavat parametrit kuin mitä määriteltävässä vessel-tietorakenteessa on. Sinun tulee sijoittaa nämä arvot luomaasi vessel - tyyppiseen muuttujaan. Kannattaa kiinnittää erityishuomiota siihen miten käsittele merkkijonoparametria name. Merkkijonosta tulee luoda kopio.
HUOM: create_vessel palauttaa paluuarvonaan kopion luomastasi vessel-tietorakenteesta, paluuarvo ei siis ole osoitin. Funktion ulkopuolella oleva koodi ei osaa vapauttaa mitään varaamaasi muistia, joten malloc:in käyttö aiheuttaa muistivuodon (ellet vapauta muistia saman tien, missä ei olisi hirveästi järkeä). Kannattaa miettiä tarvitsetko osoittimia lainkaan tässä tehtävässä.
print_vessel tulostaa annetun vessel - rakenteen sisällön siten että jokainen tietorakenteen kenttä tulostuu omalle rivilleen, mukaanlukien cargo-rakenteeseen kuuluvat kentät. Liukuluvut tulee tulostaa siten että niistä näytetään yksi desimaali. Esimerkiksi, kun edellä mainitut funktiot on toteutettu oikein, src/main.c:n esimerkkiohjelman tulisi tulostaa seuraavaa:
Apinalaiva 180.0 8.5 Bananas 10000 1500.0
Abstrakti tietotyyppi
Monimutkaisemmat (rakenteiset) tietotyypit, jotka koostuvat useista parametreista vaativat tarkkuutta: tietyt parametriyhdistelmät saattavat olla "järjettömiä", ja joskus parametrien käsittely vaatii tarkkuutta, esimerkiksi kun parametria varten on tarvittu dynaamista muistia.
Hyvä suunnitteluperiaate on eristää tällaiset ohjelman määrittelemät omat tietotyypit kukin omaksi ohjelmamodulikseen, ja piilottaa tietotyypin sisäinen toteutus ohjelmiston muilta osilta. Sen sijaan tietotyyppiä käytetään pelkästään julkisesti määriteltyjen funktioiden (eli rajapinnan) avulla, jotka pitävät huolen että tietotyypin parametreja käytetään oikein. Kun tämä tehdään oikein, tietotyypin toteutus suojautuu paremmin ohjelmointivirheiltä, joiden todennäköisyys kasvaa sitä mukaa kun ohjelmiston koko ja sen parissa työskentelevien ohjelmoijien määrä kasvaa.
Tällaista rakennetta kutsutaan abstraktiksi tietotyypiksi. Koska tietotyypin sisäinen toteutus on piilotettu muulta ohjelmalta, sitä voidaan korjata ja parannella ilman että muun ohjelmiston tarvitsee asiasta välittää. Kunhan funktiorajapinta on määritelty hyvin, ja siihen ei kosketa, muu ohjelmisto jatkaa toimintaansa normaalisti, vaikka tietotyypin sisäistä toteutusta muutettaisiinkin.
Monista muista (esim. olio-pohjaisista) ohjelmointikielistä poiketen C:ssä ei ole sisäänrakennettua mekanismia abstraktien tietotyyppien toteuttamiseksi, vaan ne pitää toteuttaa funktioiden avulla.
Tietotyyppiä varten määritellään julkinen otsaketiedosto (esim. "vector.h"), jossa kuvataan funktiorajapinta, jonka kautta tietotyyppiä käytetään. Otsaketiedostosta ei käy ilmi, miten tietotyyppi on oikeasti toteutettu. Toteutus löytyy C-kielisestä lähdetiedostosta "vector.c", mutta tietotyypin käyttäjän ei tarvitse välittää miten tietotyyppi on toteutettu.
Alla oleva esimerkki määrittelee uuden abstraktin vektoritietotyypin. "vector.h" - otsake voisi näyttää tältä:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | #ifndef AALTO_VECTOR_H #define AALTO_VECTOR_H /* Define Vector type to be used in interfaces, but don't show its internal structure */ typedef struct vector_st Vector; /* Allocates a new vector from heap, returns pointer to the vector */ Vector* vectorCreate(double x, double y, double z); /* Releases the vector from heap */ void vectorFree(Vector *v); /* Calculates sum of two vecors. Result is returned in new vector object allocated from heap */ Vector* vectorSum(const Vector *a, const Vector *b); /* Calculates the length of the vector */ double vectorLength(const Vector *v); /* Prints the vector to standard output */ void vectorPrint(const Vector *v); #endif // AALTO_VECTOR_H |
Otsakkeen alussa on esimerkki myös ns "include-vahdista" (include guard), joka estää käännösvirheet sellaisissa tilanteissa että kyseiseen otsakkeeseen viitataan useaan kertaan samassa käännösyksikössä. Tämä saattaa kuulostaa erikoiselta, mutta tilanne on kohtuullisen tavallinen suuremmissa ohjelmistoissa, joissa otsakkeet sisältävät viittauksia edelleen toisiin otsakkeisiin, ja näinollen muodostavat monimutkaisempia vittausketjuja. Palaamme myöhemmin esikääntäjä makroihin, ja siihen mitä #define ja #ifndef edellä merkitsevät.
Julkisessa rajapinnassa on hyvä olla tarkkana määreiden käytössä, ja esimerkiksi käyttää const - määrettä johdonmukaisesti ilmaisemaan, että funktio ei tule muuttamaan saamiensa parametrien sisältöä.
Vektorin sisäinen toteutus on tiedostossa "vector.c", joka sisältää varsinaisen tietorakenteen määrittelyn (vector_st) sekä sitä käyttävien funktioiden toteutuksen. Vektoria käyttävien ohjelman osien ei siis esimerkiksi tarvitse tietää kuinka tietorakenne muodostuu, koska ne käyttävät vektoria pelkästään funktioiden avulla. Alla osa vektorin toteutuksesta.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | #include <assert.h> #include "vector.h" // to ensure that the interface is compatible struct vector_st { double x, y, z; }; Vector* vectorCreate(double x, double y, double z) { Vector *v = malloc(sizeof(struct vector_st)); v->x = x; v->y = y; v->z = z; return v; } void vectorFree(Vector *v) { assert(v); // fails if v is NULL free(v); } Vector* vectorSum(const Vector *a, const Vector *b) { assert(a); // check that value is not NULL assert(b != NULL); // other way to check that value is not NULL Vector *ret = malloc(sizeof(struct vector_st)); ret->x = a->x + b->x; ret->y = a->y + b->y; ret->z = a->z + b->z; return ret; } /* ...continues with some other Vector management functions... */ |
Yllä oleva esimerkki käyttää myös assert - makroa, jolla voi varmistaa pitääkö annettu ehto paikkaansa. assert:ia käytetään silloin, kun ohjelman toiminta edellyttää esim. määritellyn osoittimen olemassaoloa. assert - ehdon epäonnistuminen keskeyttää ohjelman oletusarvoisesti välittömästi. Kun ohjelma toimii oikein, assert - ehtojen tulisi siis aina olla tosia, mutta niitä halutaan käyttää varmistamaan "vahvoja oletuksia" ohjelman toimintaan liittyen. Kehitysvaiheessa halutaan saadaan selkeä varoitus tilanteista, joissa nämä vahvat oletukset pettävät, jotta päästään korjaamaan virheen syy. assert - makro määritellään "assert.h" - otsakkeessa.
Kun abstrakti tietotyyppi on määritelty, muualla ohjelmassa on sisällytettävä sen määrittävä otsaketiedosto (tässä "vector.h"). Varsinaisesta C-lähdetiedostosta emme ole kiinnostuneita. Nyt vektoreita voi käsitellä vain annettuja funktioita kutsumalla, kuten alla nähdään:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | #include "vector.h" int main(void) { // create two vectors and calculate their sum into third vector Vector *v1 = vectorCreate(1, 3, 4); Vector *v2 = vectorCreate(0, -2, 2); Vector *v3 = vectorSum(v1, v2); // print the result vectorPrint(v3); // release all three vectors that were allocated vectorFree(v1); vectorFree(v2); vectorFree(v3); } |
Task 05_fraction: Murtoluku (4 pts)
Nyt harjoitellaan abstraktin datatyypin tekemistä toteuttamalla uusi numerotyyppi, murtoluku (fraction), joka koostuu osoittajasta (numerator) ja nimittäjästä (denominator). Esimerkiksi 2/3 ja 4/6 ovat murtolukuja, joissa 2 ja 4 ovat osittajia, ja 3 ja 6 nimittäjiä. Nämä murtoluvut ovat myös yhtä suuria. Määrittelemme uuden tietotyypin Fraction esittämään murtolukuja.
Tässä tehtävässä sinun tulee toteuttaa seuraavat funktiot. Kustakin funktiokokonaisuudesta saa yhden pisteen, ja tehtävä on siten kokonaisuudessaan neljän pisteen arvoinen.
Tehtävässä annetaan otsake fraction.h, joka määrittelee julkisen rajapinnan, jonka kautta murtolukuja käsitellään. Sinun tulee toteuttaa funktiot ja tarvitsemasi tietorakenteet tiedostoon fraction.c.
(a) Aseta arvo
Toteuta funktio Fraction* setFraction(unsigned int numerator,
unsigned int denominator) joka varaa uuden murtoluvun dynaamisesti
keosta ja asettaa sen esittämään lukua, jonka osoittaja ja nimittäjä
parametreissa annetaan. Funktion tulee palauttaa luotu murtoluku (eli
osoitin siihen).
Lisäksi sinun tulee toteuttaa seuraavat yksinkertaiset funktiot:
-
void freeFraction(Fraction* f)joka vapauttaa murtoluvulle varatun muistin. -
unsigned int getNum(const Fraction *f)joka palauttaa annetun murtoluvun osoittajan. -
unsigned int getDenom(const Fraction *f)joka palauttaa annetun murtoluvun nimittäjän.
(b) Vertaile arvoja
Toteuta funktio int compFraction(const Fraction *a, const
Fraction *b) joka palauttaa -1, mikäli murtoluku a on pienempi kuin
b, 0 mikäli murtoluvut ovat yhtä suuria, tai 1, mikäli murtoluku a
on suurempi kuin b. Funktion tulee toimia oikein myös silloin kun
nimittäjät ovat erisuuria.
Huom: Seuraavia tehtäväkohtia koskevat testit käyttävät tätä toteutustasi testaamaan funktioiden toimintaa. Siksi sinun tulee toteuttaa tämä tehtäväkohta oikein, ennenkuin siirryt tehtäväkohtiin (c) ja (d).
(c) Summalasku
Toteuta funktio Fraction *add(const Fraction *a, Fraction *b) joka
laskee murtolukujen a ja b summan, ja palauttaa tuloksena syntyvän
uuden murtoluvun paluuarvonaan. Palautettava tulos on uusi
murtolukuobjekti, joka varataan dynaamisesti. Funktion tulee toimia
oikein myös silloin kun summattavien lukujen nimittäjät poikkeavat
toisistaan. Lopputulosta ei tarvitse supistaa käyttämään pienintä
mahdollista nimittäjää.
Vinkki: kannattaa aloittaa muuntamalla summattavat murtoluvut sellaisiksi, että ne käyttävät samaa nimittäjää.
(d) Supista murtoluku
Toteuta funktio void reduce(Fraction *val)
joka supistaa annetun murtoluvun pienimpään mahdolliseen
nimittäjään. Esimerkiksi jos val esittää murtolukua 3/6, sen tulisi
supistua murtoluvuksi 1/2. Pienimmän nimittäjän etsiminen onnistuu
hakemalla pienin yhteinen tekijä osoittajalle ja
nimittäjälle. Tehtäväpohjasta löytyy valmiiksi annettu funktio
unsigned int gcd(unsigned int u, unsigned int v) jonka avulla tämä
onnistuu. (funktion toteutus on otettu
wikipediasta)
Task 06_oodi: Oodi (3 pts)
Tavoite: Harjoittele dynaamisesti varattujen ja kokoaan muuttavien taulukoiden käyttöä tietorakenteista koostetuista alkioista.
Tässä tehtävässä toteutat yksinkertaisen tietokannan kurssiarvosanojen
tallentamiseen. Tietokannan jokainen tietue noudattaa struct oodi
rakennetta, ja tietokanta muodostuu dynaamisesti varatusta taulukosta,
jossa siis on useita struct oodi - instansseja peräkkäin. Aina kun
uusi alkio lisätään taulukkoon, pitää varmistua että taulukolle on
varattu riittävästi muistia uuden alkion tallentamiseen.
struct oodi - määrittely ja sen kenttien kuvaukset löytyvät tiedostosta oodi.h. Kannattaa perehtyä tietorakenteen määrittelyyn ja selvittää itselleen mitkä kentät saavat tarvitsemansa tilan osana tietorakennetta, ja mille kentille tarvittava tila pitää varata erikseen. Esimerkiksi kenttä course on merkkijono, jolle pitää dynaamisesti varata tarvittu tila erikseen.
Harjoituksessa on kolme kohtaa, joista kustakin saa yhden pisteen. Kannattaa toteuttaa tehtäväkohdat annetussa järjestyksessä, koska myöhemmät tehtäväkohdat saattavat riippua aiemmin toteutetuista funktioista. Kannattaa myös testata ohjelmaasi jokaisen tehtäväkohdan välissä, ja mikäli se näyttää toimivan, lähettää pisteytystä varten palvelimelle. Vaikka koko tehtävä ei olisikaan valmis, yksittäisistä tehtäväkohdista voi silti saada pisteitä.
(a) Alusta opiskelijatietue
Toteuta funktio 'init_record' joka alustaa annetun oodi - rakenteen osoittimen or osoittamassa paikassa saamiensa parametrien (p_student, p_course, jne...) pohjalta. Sinun ei tarvitse varata muistia tässä tehtäväkohdassa, vaan voit olettaa että or - osoitin viittaa muistialueeseen jossa on riittävästi tilaa varattuna. Sinun tulee kuitenkin varata muistia niille rakenteen kentille, joiden vaatima tila ei sisälly oodi - rakenteeseen. Kannattaa esimerkiksi kiinnittää huomiota merkkijonoihin.
Funktio palauttaa arvon 1, jos alustus onnistui, tai 0 jos se epäonnistui jostain syystä. Funktio epäonnistuu esimerkiksi silloin, jos sille annetaan virheellinen opiskelijanumero, jossa on enemmän kuin 6 merkkiä. Voit olettaa että mikä tahansa 6 merkkiä pitkä (tai lyhyempi) merkkijono on hyväksyttävä opiskelijanumero.
(b) Lisää uusi tietue
Toteuta funktio 'add_record' joka lisää uuden oodi - tietorakenteen dynaamisesti varatun taulukon loppuun, ja tarvittaessa varaa taulukolle lisää tilaa. Osoitin taulukon alkuu tulee funktioparametrissa array, ja taulukon nykyinen pituus parametrissa length. Lisättävä tieto annetaan parametrissa newrec. On syytä huomioida että newrec:n sisältö tulee kopioida taulukkoon oikealle paikalle, ja jälleen kannattaa kiinnittää huomiota osoittimien käsittelyyn.
Funktio palauttaa osoittimen taulukkoon lisäyksen jälkeen. Tämähän saattaa olla eri osoite kuin se, joka array - parametrissa annettiin sisään.
(c) Päivitä arvosanaa
Toteuta funktio change_grade, joka päivittää arvosanaa (newgrade) ja suorituspäivää (newdate) taulukossa olevaan alkioon. Muutettava taulukon alkio tunnistetaan opiskelijanumerolla (p_student) ja kurssikoodilla (p_course). Molempien pitää täsmätä, jotta muutos voidaan tehdä. Mikäli vastaavaa alkiota ei löydy, funktio ei muuta mitään. Funktio palauttaa arvon 1, mikäli jotain alkiota muutettiin, tai 0, mikäli vastaavaa taulukon alkiota ei löytynyt, eikä muutosta näin ollen tehty. Voit olettaa että kukin opiskelijanumero/kurssikoodi - yhdistelmä esiintyy taulukossa korkeintaan kerran.
Linkitetty lista
Linkitetty lista on yleinen tietorakenne, jonka avulla dynaamisesti varatuista solmuista voidaan tehokkaasti muodostaa järjestetty lista. Linkitetty lista poikkeaa taulukosta siinä, että kukin alkio on varattu muistista erikseen, eivätkä alkiot välttämättä sijaitse peräkkäisissä kohdissa muistia. Sen sijaan alkiot on ketjutettu toisiinsa osoittimien avulla.
Jos oletetaan, että meillä on yksinkertainen linkitetty lista, jonka kuhunkin solmuun tallennetaan yksi kokonaisluku, tarvitsemme seuraavanlaisen tietorakenteen:
1 2 3 4 | struct intlist { int value; struct intlist *next; }; |
Varsinaisen kokonaislukualkion lisäksi tarvitaan siis osoitin samantyyppiseen intlist rakenteeseen, josta löytyy seuraava listaan tallennettu kokonaisluku. Listan voi visualisoida seuraavalla tavalla:
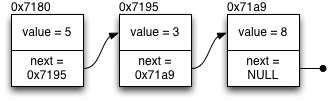
Linkitettyä listaa käyttävällä ohjelmalla on tyypillisesti vain osoitin listan ensimmäiseen alkioon. Jos esimerkiksi listasta etsitään jotain tiettyä alkiota, ohjelman pitää siis alkaa seuraamaan next - osoittimien ketjua listan alkioita eteenpäin. Listan viimeisen alkion tunnistaa siitä, että sen next - osoitin on NULL.
Seuraava ohjelma tulostaa kaikki linkitettyyn listaan tallennetut alkiot.
1 2 3 4 5 6 7 8 9 | struct intlist *first; // alusta linkitetty lista jollain tapaa... struct intlist *current = first; while (current) { // toista, kunnes NULL-osoitin tulee vastaan printf("value: %d\n", current->value); current = current->next; } |
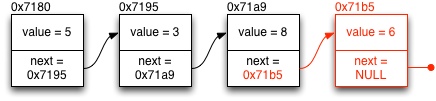
Kun linkitetyn listan loppuun lisätään uusi alkio, seuraavat toimenpiteet tarvitaan:
-
Varaa muistia uudelle listan alkiolle: esimerkiksi yllä olevan listan tapauksessa:
struct intlist *new = malloc(sizeof(struct intlist));. Alusta varatun tietorakenteen kentät haluamallasi tavalla. Koska uudesta alkiosta tulee listan viimeinen alkio, next - osoittimeksi asetetaan NULL. -
Etsi tämän hetkisen listan viimeinen alkio etenemällä listaa next - osoittimia käyttäen. Viimeisen alkion tunnistaa siitä, että next - osoitin on NULL (
current->next == NULL, tms). -
Muokkaa (aiemman) viimeisen alkion next - osoitinta siten, että se viittaa askelessa 1 varaamaasi uuteen tietosolmuun. (
current->next = new, tms.). Nyt varaamasi uusi alkio on linkitetty listan loppuun.
Sama diagrammin avulla esitettynä:
Kun listasta poistetaan alkio, poistettavaa edeltävä next - osoitin tulee päivittää siten, että se "ohittaa" poistettavan alkion, ja viittaa sitä seuraavaan alkioon. Tai mikäli poistettava alkio sattuu olemaan listan lopussa, edeltäväksi next - osoittimeksi asetetaan NULL merkkaamaan listan loppua. Poistettavalle alkiolle varattu muisti tulee tietysti tässä vaiheessa vapauttaa free - kutsulla.
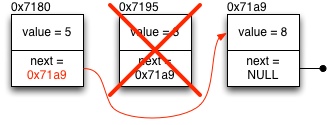
Linkitetyn listan käsittelyssä tulee erityisesti kiinnittää huomiota listan alku- ja loppupään käsittelyyn. Miten esimerkiksi toimitaan, kun listan ensimmäinen alkio poistetaan?
On hyvä vertailla edellä esitettyä kahta vaihtoehtoista tapaa dynaamisesti kokoaan vaihtavan listan tallentamiseen:
-
dynaamisesti varattu taulukko vaatii koko taulukon uudelleen varaamisen, kun kokoa tarvitsee muuttaa. Toisaalta taulukon mihin tahansa alkioon on nopea päästä käsiksi taulukkoa normaalisti indeksoimalla.
-
Linkitettyyn listaan on nopea lisätä ja poistaa alkioita. Toisaalta listan keskellä olevaan alkioon pääsee käsiksi vain seuraamalla linkitetyn listan osoittimia, mikä on hitaampaa kuin taulukon indeksointi.
Linkitetty lista on malliesimerkki tietotyypistä, joka olisi hyvä esittää abstraktina tietotyyppinä, pelkästään hyvin määritellyn rajapinnan kautta, jotta muualta ohjelmasta ei ohjelmointivirheiden seurauksena vahingossa sotketa listan rakennetta.
Task 07_queue: Harjoitusjono (3 pts)
Tavoite: Harjoittele tietorakenteiden ja osoittimien pyörittelyä linkitetyn listan avulla.
Tässä tehtävässä toteutetaan yksikertainen jonotusjärjestelmä opiskelijoita varten. Kukin jonon alkio sisältää opiskelijanumeron sekä opiskelijan nimen. Jono toteutetaan abstraktina tietotyyppinä Queue, ja sen käsittelyyn tarvittavat funktiot toteutetaan tiedostossa queue.c. queue.h määrittelee julkisen rajapinnan jonon käsittelyyn ja queuepriv.h sisältää määrittelyt jotka ovat jonototeutuksen sisäisiä, ja jota toisten ohjelmamodulien ei tarvitse tuntea. Jono toteutetaan linkitettynä listana.
Tässä linkitetyn listan variaatiossa ylläpidetään osoitinta sekä ensimmäiseen listan alkioon että viimeiseen listan alkioon, sen lisäksi että listan alkiot yhdistetään toisiinsa next - osoittimien avulla. Listan viimeisen alkion next osoitin on aina NULL.
Alkutilanteessa osoittimet first ja last ovat NULL-osoittimia. Kun listaan lisätään ensimmäinen (ja ainut) alkio, molemmat osoittimet siiretään osoittamaan siihen. Tämän jälkeen uudet lisäykset listaan aiheuttavat last - osoittimen siirtymisen, mutta first - osoitin jää jonon ensimmäisen alkion kohdalle.
Listaa käydään läpi seuraamalla next - osoittimia alkio kerrallaan. Kun lisäät alkion listan loppuun, sinun tulee siis päivittää edellisen alkion next - osoitinta (joka sitä ennen oli NULL), sekä lisäksi last - osoitinta.
Listan jokainen alkio varataan erikseen dynaamisesti muistista.
Jotkut funktiot Queue - tyypin käsittelyksi on jo valmiiksi toteutettu, mutta tärkeimmät funktiot sinun tulee toteuttaa. Nämä ovat seuraavat:
(a) Lisää opiskelija jonoon
Toteuta funktio 'Queue_enqueue' joka lisää uuden opiskelijan jonon perään. Funktio saa parametrikseen osoittimen tämän hetkiseen jonoon (q), sekä lisättävän opiskelijan opiskelijanumeron (id), sekä nimen (name). Funktio palauttaa arvon 1, mikäli lisäys onnistui tai 0, mikäli se epäonnistui. Mikäli opiskelijanumero on virheellinen (enemmän kuin 6 merkkiä), funktion ei tule lisätä mitään, vaan palauttaa 0. Koska opiskelijan nimen pituus ei ole tiedossa, eikä sitä voida varata osana jonotietorakennetta, se pitää varata erikseen dynaamisesti, kuten uuden jonoelementin vaatima tilakin.
Sinun ei tarvitse tarkistaa löytyykö opiskelija jo ennestään jonosta.
Testaamisen ja debugaamisen helpottamiseksi kannattaa hyödyntää main.c - tiedostoa ja sillä tuotettavaa src/main - ohjelmaa ennenkuin tehtävä lähetetään TMC:n tarkistettavaksi.
(b) Ota jonon ensimmäinen
Toteuta funktio 'Queue_dequeue' joka poistaa jonon ensimmäisen alkion ja vapauttaa sille varatun muistin. Funktio palauttaa arvon 1, mikäli jotain otettiin jonon kärjestä pois, tai 0 mikäli mitään ei poistettu (esimerkiksi jos jono oli jo ennestään tyhjä).
Tämä rajapinta mahdollistaa sen, että koko jonon saa kerralla tyhjäksi
lauseella while (Queue_dequeue(queue));.
(c) Tiputa annettu alkio
Toteuta funktio 'Queue_drop' joka poistaa annetun opiskelijanumeron jonosta, ja vapauttaa sen tarvitseman muistin. Kyseinen alkio voi sijaita missä jonon kohdassa tahansa, ja poiston jälkeen jonon pitää säilyä edelleen eheänä ja toimintakuntoisena, eli kaikki osoittimet pitää päivittää asiaan kuuluvasti.
Funktio palauttaa arvon 1, mikäli annettua opiskelijanumeroa vastaava opiskelija löytyi ja se poistettiin, tai 0, mikäli kyseistä opiskelijaa ei löytynyt, eikä mitään poistettu. Kukin funktiokutsu poistaa vain yhden alkion: jos opiskelija sattuu olemaan jonossa useamman kerran, vain ensimmäinen täsmäävä alkio poistetaan.